IGLU
Integrated Gaussian Linear Unit
TL;DR
IGLU: Integrated Gaussian Linear Unit is a parametric activation function derived as a scale mixture of GELU gates under a half-normal distribution. This derivation yields a closed-form expression whose gating component is exactly the Cauchy CDF, providing a principled one-parameter family that continuously interpolates between identity-like and ReLU-like behavior via a single sharpness parameter $\sigma$. Unlike GELU’s Gaussian gate, IGLU’s heavy-tailed Cauchy gate decays polynomially in the negative tail, guaranteeing non-zero gradients for all finite inputs and offering greater robustness to vanishing gradients.
Paper
IGLU: The Integrated Gaussian Linear Unit Activation Function
Mingi Kang, Zai Yang, Jeova Farias Sales Rocha Neto
Bowdoin College
Proceedings of the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD), 2026. arXiv:2603.06861
Key Contributions
- Derives IGLU as a continuous scale mixture of GELU gates under half-normal distribution
- Gating component equals Cauchy CDF—guarantees non-zero gradients for all finite inputs
- IGLU-Approx: efficient rational approximation using only ReLU operations (no transcendental functions)
- Demonstrates strong performance on balanced and especially imbalanced datasets
- Provides theoretical unification of ReLU and GELU via single parameter $\sigma$
Integrated Gaussian Linear Unit
First recall the definition of GELU:
\[\text{GELU}(x) = x \cdot \Phi(x), \Phi(x) = \int_{-\infty}^{x} \frac{1}{\sqrt{2\pi}} e^{-\frac{t^2}{2}} dt\]Since GELU follow the gated-linear form $x \cdot g(x)$, we can introduce a configurable parameter $a$ that scales or sharpens the gate, producing parameterized variants:
\[\text{GELU}_a(x;a) = x \cdot \Phi(a x)\]As $a$ approaches infinity, the function converge to ReLU, and as $a$ approaches zero, the function converge to a scaled identity function.
Rather than a single parameter level $a$, we can introduce it as a latent scale variable and average over a continuum of gating strengths:
\[\text{IGLU}(x; \sigma) = \int_{0}^{\infty} \text{GELU}_a(x; a) f(a;\sigma)da,\]where $f(a;\sigma)$ is a non-negative weighting function parameterized by $\sigma > 0$. This formulation allows the activation function to adaptively integrate information across a range of gating strengths, potentially enhancing its expressiveness and performance in neural networks.
Now, when we choose $f(a;\sigma)$ to be a half-normal distribution with mean zero and standard deviation $\sigma$, the integral becomes:
\[Z(x; \sigma) = \int_{0}^{\infty} \Phi(a x) \cdot \frac{\sqrt{2}}{\sigma \sqrt{\pi}} e^{-\frac{a^2}{2\sigma^2}} da,\]where $\text{IGLU}(x; \sigma) = x \cdot Z(x; \sigma)$.
To solve this integral, we expand $\Phi(ax)$ and substitute $t = ax$:
\[Z(x;\sigma) = \frac{2x}{\sqrt{2\pi}\,\sigma} \int_0^\infty e^{-a^2/2\sigma^2} \int_{-\infty}^{x} \frac{a}{\sqrt{2\pi}}\, e^{-a^2 s^2/2}\, ds\, da.\]We then swap the order of integration and solve the inner integral:
\[= \int_0^\infty a\, e^{-a^2\left(\frac{1}{\sigma^{2}} + s^2\right)/2} da = \frac{1}{\sigma^{-2} + s^2} = \frac{\sigma^2}{1 + \sigma^2 s^2},\]which leads to the closed-form solution for $Z(x; \sigma)$:
\[Z(x;\sigma) = \frac{\sigma x}{\pi} \int_{-\infty}^{x} \frac{ds}{1 + \sigma^2 s^2} = \frac{1}{2} + \frac{\arctan(\sigma x)}{\pi},\]and thus the final closed-form expression for IGLU is:
\[\text{IGLU}(x; \sigma) = x \cdot Z(x; \sigma) = x \left( \frac{1}{2} + \frac{\arctan(\sigma x)}{\pi} \right)\]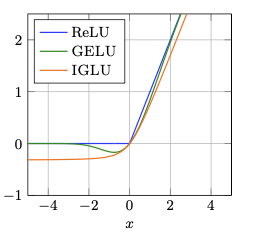
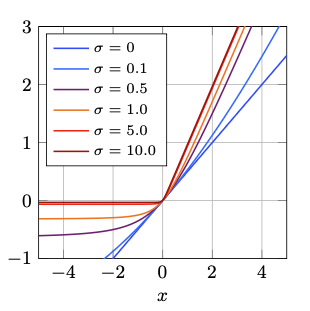
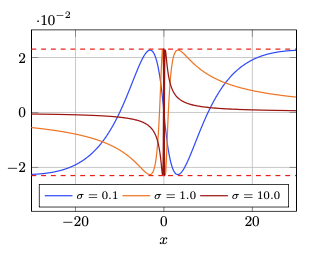
Integrated Gaussian Linear Unit Approximation
The approximation for the arctangent function:
\[\arctan(x) \approx \frac{\pi}{2} \cdot \frac{\sigma x}{1 + |\sigma x|},\]which is continuous, odd, and saturates correctly as $x \to \pm \infty$. Substituting into the original gating function yields:
\[Z_{\text{approx}}(x; \sigma) = \frac{1}{2} \frac{1 + 2\max(0, \sigma x)}{1 + |\sigma x|} = \frac{1}{2} \frac{1 + 2\text{ReLU}(\sigma x)}{1 + \text{ReLU}(\sigma x) + \text{ReLU}(-\sigma x)},\]where we used the identities $x + \lvert x\rvert = 2\max(0, x)$ and $\lvert x\rvert = \max(0, x) + \max(0, -x)$.
This approximation maintains the same asymptotic behavior as the original function while being computationally more efficient to evaluate.
Therefore, the final approximation for IGLU is:
\[\text{IGLU}_{\text{approx}}(x; \sigma) = x \cdot Z_{\text{approx}}(x; \sigma) = \frac{x}{2} \cdot \frac{1 + 2\text{ReLU}(\sigma x)}{1 + \text{ReLU}(\sigma x) + \text{ReLU}(-\sigma x)}\]Computational Efficiency
IGLU-Approx benchmarks (relative to Identity function):
- CPU Forward: 10.17× (vs GELU: 16.40×)
- GPU Forward: 15.05× (vs GELU: 15.36×)
- Competitive with ReLU while preserving smooth gradient flow
- No transcendental function evaluation required
Citation
@article{kang2026iglu,
title={IGLU: The Integrated Gaussian Linear Unit Activation Function},
author={Kang, Mingi and Yang, Zai and Neto, Jeova Farias Sales Rocha},
journal={arXiv preprint arXiv:2511.XXXXX},
year={2026}
}